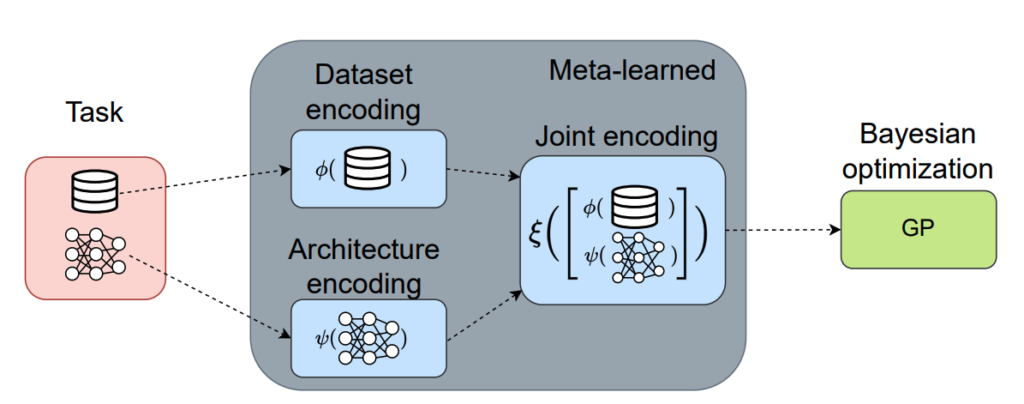
Neural Architecture Search (NAS) is a field that, despite making progress, still encounters significant computational expenses and limited generalizability when applied to various datasets and search spaces. Our ICLR 2023 paper “Transfer NAS with Meta-Learned Bayesian Surrogates” is a research endeavour that aims to address these issues by employing Bayesian optimization in a combined space of datasets and network architectures. This approach leverages prior knowledge regarding architecture performance across different datasets while also ensuring exploration of the architecture space.
The proposed methodology utilizes a set encoder based on transformer models to encode the datasets, a graph neural network to encode the architectures, and a fully connected neural network to learn a joint embedding of these representations. Together, these components form the deep kernel that is used to perform Bayesian optimization in the joint space of datasets and neural architectures. The embeddings from the deep kernel are fed to a Gaussian Process surrogate for standard Bayesian optimization.
Transfer NAS (TNAS) excels in both anytime-performance and final performance, surpassing classical HPO methods like HEBO which won the 2020 NeurIPS blackbox optimization challenge, as well as NAS-adapted HPO methods like BANANAS and NASBOWL. It is also competitive with one-shot approaches in terms of runtime, and far more robust.
In future extensions of this work, it is possible to incorporate not only the interaction between architecture embeddings and dataset meta-features but also the hyperparameter configurations of the training pipeline. These hyperparameter configurations are known to have an impact on the performance of a given architecture.