Fairness in AI is a complex and evolving challenge that continues to spark intense debate and research in the tech community. As we grapple with the ethical implications of AI decision-making, we proposed a new approach called ManyFairHPO, offering a fresh perspective on this critical issue. While not a silver bullet, this innovative framework presents an intriguing way to navigate the multifaceted nature of algorithmic fairness. By considering multiple, often conflicting notions of fairness simultaneously, ManyFairHPO opens up exciting possibilities for creating more nuanced and context-aware AI systems.
The Fairness Dilemma
When it comes to fairness in AI, we quickly realize that “fair” means different things to different people. Various stakeholders – from policymakers and business leaders to civil rights advocates and affected communities – may prioritize different aspects of fairness. For instance, a university admissions officer might focus on demographic parity, while a loan officer might prioritize equal opportunity. These differing perspectives translate into multiple, sometimes conflicting fairness metrics.
But here’s the challenge: optimizing for one fairness metric can inadvertently worsen another, potentially leading to unintended consequences. For example, a model that achieves statistical parity in hiring might inadvertently reinforce stereotypes or contribute to a “self-fulfilling prophecy” effect. The complex interplay between these metrics and their real-world impacts raises a critical question: How can we design AI systems that balance multiple fairness objectives without causing harmful side effects?
This is where ManyFairHPO comes in, offering a novel approach to navigate the intricate landscape of fairness in AI.
Introducing ManyFairHPO

Enter ManyFairHPO, a novel framework developed to tackle this very challenge. Unlike traditional approaches that focus on a single fairness metric, ManyFairHPO treats fairness as a many-objective optimization problem. Here’s how it works:
- Many-Objective Optimization: The framework begins by exploring trade-offs between accuracy and multiple fairness metrics simultaneously. This process generates Pareto Fronts – sets of solutions where improving one objective (e.g., accuracy) without worsening another (e.g., a fairness metric) is impossible. These Pareto Fronts provide a comprehensive view of the trade-offs between different performance and fairness metrics, allowing practitioners to understand the full spectrum of possible solutions.
- Fairness Metric Selection & Risk Identification: In this crucial step, the goal is to assign weights to different fairness metrics based on their relative importance. This process involves two key inputs: stakeholder preferences and exploratory analysis. Stakeholders from diverse backgrounds can express their priorities, ensuring that a wide range of perspectives is considered in the decision-making process. Simultaneously, practitioners conduct an exploratory analysis of the Pareto Fronts to identify conflicts between fairness metrics specific to the problem at hand. This analysis helps uncover potential risks associated with different model choices, such as unintended biases or negative feedback loops. By combining stakeholder input with data-driven insights, this step aims to create a nuanced understanding of which fairness metrics are most critical for the specific context, while also identifying potential negative downstream consequences that could arise from prioritizing certain metrics over others.
- Fairness-Aware Model Selection: Building on the insights from the previous steps, this final stage enables users to select models that best balance multiple objectives. With the weighted fairness metrics determined in step 2, practitioners can now navigate the Pareto Fronts more effectively. They can choose models that not only perform well but also align with the prioritized fairness criteria and mitigate identified risks. This approach ensures that the selected model reflects a carefully considered balance between performance, various notions of fairness, and potential real-world impacts.
Why It Matters
ManyFairHPO isn’t just another technical improvement – it represents a fundamental shift in how we approach fairness in AI. Here’s why it’s so important:
- Context Awareness: By considering multiple fairness metrics, ManyFairHPO allows for more nuanced and context-appropriate solutions.
- Risk Mitigation: The framework helps identify and mitigate potential downstream risks associated with fairness trade-offs.
- Stakeholder Alignment: Its human-in-the-loop approach facilitates better alignment between technical solutions and diverse stakeholder priorities.
- Transparency: Throughout the process, ManyFairHPO provides interpretable results, increasing transparency in decision-making.
Real-World Impact
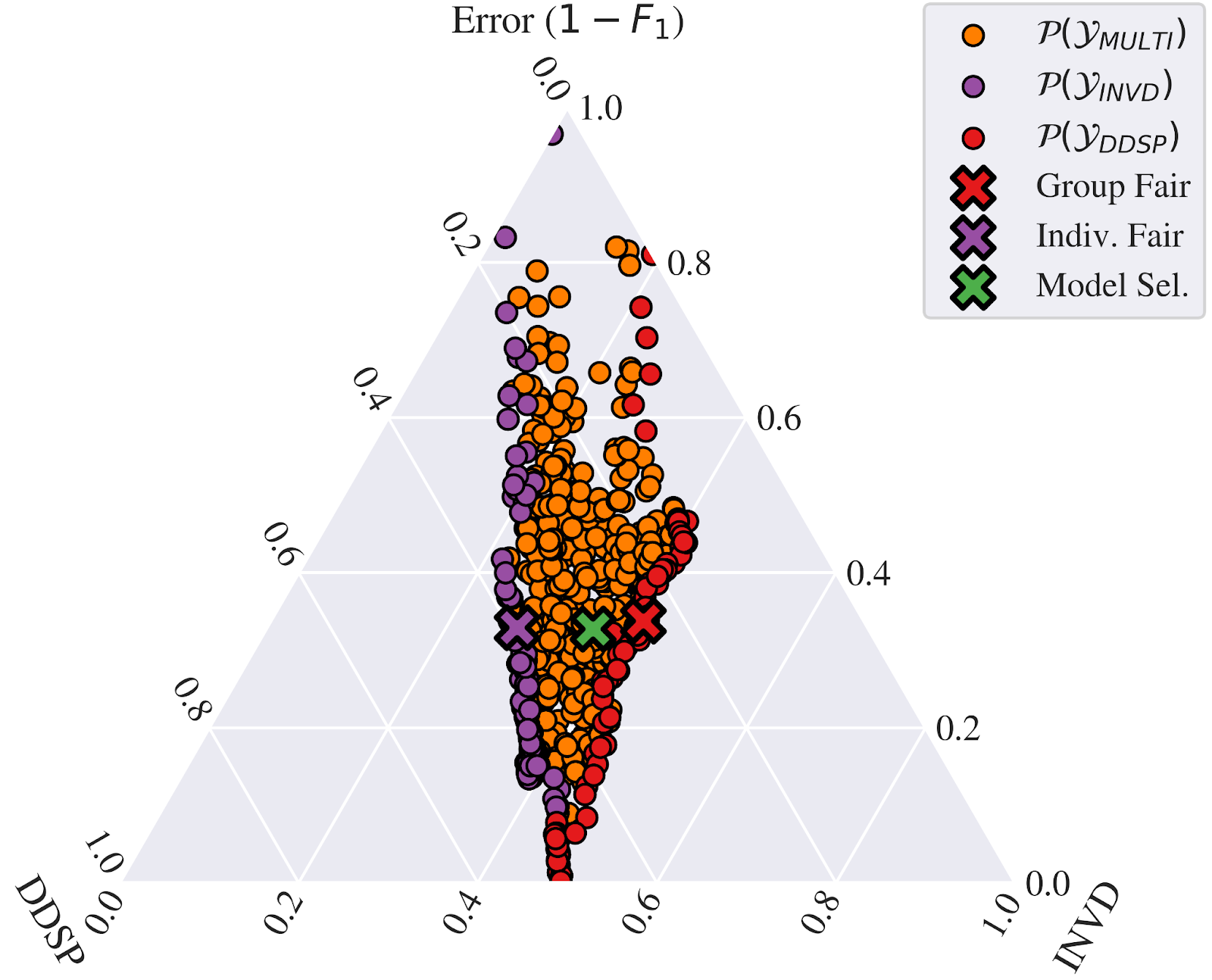
Building on the framework described above, we applied ManyFairHPO to a law school admissions scenario, balancing three fairness metrics: Demographic Statistical Parity (DDSP), Equal Opportunity (DEOP), and Inverse Distance (INVD).
Initially, stakeholders prioritized accuracy and DDSP equally. However, ManyFairHPO revealed a conflict between individual (INVD) and group fairness metrics (DDSP, DEOP). Models optimizing for group fairness accepted more underprivileged applicants, including some less prepared academically.
Recognizing the risk of a self-fulfilling prophecy, stakeholders adjusted the weights assigned to various objectives: Accuracy was prioritized at 0.5, while Demographic Disparity Score Parity (DDSP) received a weight of 0.2, and Individual Non-Discrimination Value (INVD) was set at 0.3.
This led to a model balancing diversity with individual fairness, mitigating the risk of reinforcing negative stereotypes while maintaining a diverse student body. The case study demonstrates ManyFairHPO’s ability to navigate complex fairness trade-offs and anticipate long-term consequences in high-stakes scenarios.

Looking Ahead
While ManyFairHPO represents a significant advancement, it also opens up new avenues for research and development:
- Expanding the optimization space: Currently, ManyFairHPO operates within the constraints of hyperparameter optimization, which limits the range of achievable fairness metric and performance values. A promising direction for improvement is to incorporate a wider array of bias mitigation techniques and their associated hyperparameters into the optimization process. This expansion would not only enhance ManyFairHPO’s performance but also provide deeper insights into fairness metric conflicts. By exploring a broader solution space, we could uncover more nuanced trade-offs and potentially find solutions that better balance multiple fairness criteria while maintaining high performance.
- Further socio-technical studies on fairness metric conflicts and their contextual relevance: As we continue to apply ManyFairHPO to diverse real-world scenarios, we’ll gain valuable insights into how fairness metric conflicts manifest in different contexts. This research could lead to a better understanding of which conflicts are most critical in specific domains and help develop guidelines for prioritizing fairness metrics in various applications.
The Bottom Line
ManyFairHPO isn’t just a tool—it’s a paradigm shift in how we approach fairness in AI. By recognizing the inherent complexity of fairness and offering a framework to navigate it, ManyFairHPO empowers practitioners to make more responsible, context-aware decisions. As AI continues to permeate critical sectors of society, approaches like this will be essential in ensuring that our algorithms are not only powerful but also fair and equitable.
The journey toward truly fair AI is ongoing, but with innovations like ManyFairHPO, we’re making meaningful strides in the right direction.