Tabular data is the ubiquitous in every area of commerce, healthcare, industry and society. With Machine Learning playing such a pivotal role in understanding and utilizing this data, AutoML aims to make this more efficient, robust and practical for non-machine learning experts, who know more about their domain than machine learning.
TabPFN
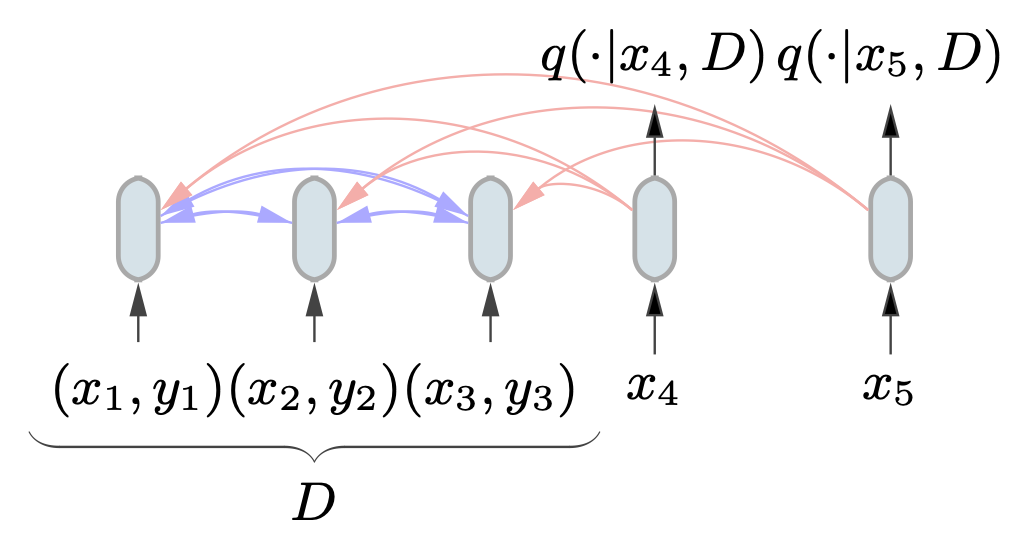
TabPFN is a transformer model that is train on synthetic data generated from a prior, a synthetic function which models how real tabular data might look in the world. By sampling from this prior, TabPFN can transfer to new datasets with ease, while producing blazing fast predictions in a single forward-pass of the network. This achieved State-of-the-Art on the de-facto benchmark for AutoML systems, with a dominating performance in numerical datasets. The impact of this paper resulted in an oral presentation at ICLR 2023.
Usage
from tabpfn import TabPFNClassifier classifier = TabPFNClassifier() classifier.fit(X_train, y_train) y_eval, p_eval = classifier.predict(X_test, return_winning_probability=True)
Here you can find a link to the official github repo!
Blogs
References
- Noah Hollmann, Samuel Müller, Katharina Eggensperger and Frank Hutter:
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
In: The Eleventh International Conference on Learning Representations, 2023
Auto-Sklearn
Auto-sklearn provides out-of-the-box supervised machine learning. Built around the scikit-learn machine learning library, auto-sklearn automatically searches for the right learning algorithm for a new machine learning dataset and optimizes its hyperparameters. Thus, it frees the machine learning practitioner from these tedious tasks and allows her to focus on the real problem.

Usage
auto-sklearn is written in python and is a drop-in replacement for scikit-learn classifiers:
import autosklearn.classification cls = autosklearn.classification.AutoSklearnClassifier() cls.fit(X_train, y_train) predictions = cls.predict(X_test)
Here you can find a link to the official github repo!
Background
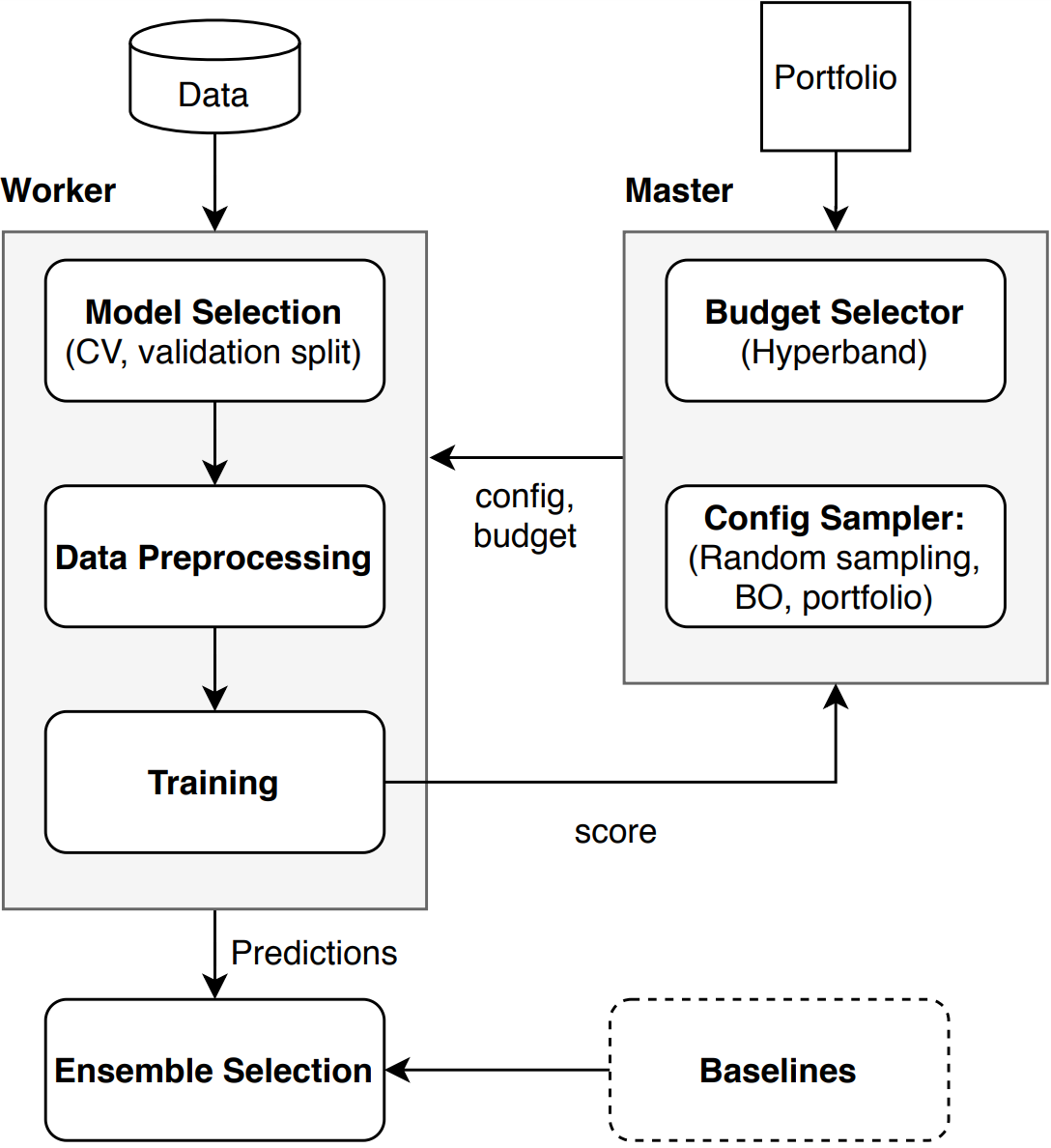
Auto-sklearn extends the idea of configuring a general machine learning framework with efficient global optimization which was introduced with Auto-WEKA. To improve generalization, auto-sklearn builds an ensemble of all models tested during the global optimization process. In order to speed up the optimization process, auto-sklearn uses meta-learning to identify similar datasets and use knowledge gathered in the past. Auto-sklearn wraps a total of 15 classification algorithms, 14 feature preprocessing algorithms and takes care about data scaling, encoding of categorical parameters and missing values.
Competitions
We developed auto-sklearn to participate in the ChaLearn Automatic Machine Learning Challenge. Using auto-sklearn, we won six out of 10 track in the 1st competition and the main track of the 2nd competition. You can read an overview paper by the competition organizers here.
Blogs
References
- Feurer, Matthias and Eggensperger, Katharina and Falkner, Stefan and Lindauer, Marius and Hutter, Frank
Auto-sklearn 2.0: The Next Generation - Feurer, Matthias and Eggensperger, Katharina and Falkner, Stefan and Lindauer, Marius and Hutter, Frank
Practical Automated Machine Learning for the AutoML Challenge 2018
In: ICML 2018 AutoML Workshop - Feurer, M. and Klein, A. and Eggensperger, K. and Springenberg, J. and Blum, M. and Hutter, F.
Efficient and Robust Automated Machine Learning
In: Advances in Neural Information Processing Systems 28
Auto-PyTorch
While early AutoML frameworks focused on optimizing traditional ML pipelines and their hyperparameters, another trend in AutoML is to focus on neural architecture search. To bring the best of these two worlds together, we developed Auto-PyTorch, which jointly and robustly optimizes the network architecture and the training hyperparameters to enable fully automated deep learning (AutoDL). Auto-PyTorch achieved state-of-the-art performance on several tabular benchmarks by combining multi-fidelity optimization with portfolio construction for warmstarting and ensembling of deep neural networks (DNNs) and common baselines for tabular data.
The API is inspired by auto-sklearn and only requires a few inputs to fit a DL pipeline on a given dataset.
Usage
autoPyTorch = AutoNetClassification("tiny_cs", max_runtime=300, min_budget=30, max_budget=90)
autoPyTorch.fit(X_train, y_train, validation_split=0.3)
y_pred = autoPyTorch.predict(X_test)
print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_pred))
If you are interested in Auto-PyTorch, you can find our open-source implementation here:
Blogs
References
- Lucas Zimmer, Marius Lindauer and Frank Hutter: Auto-PyTorch Tabular: Multi-Fidelity Meta Learning for Efficient and Robust AutoDL In: IEEE Transactions on Pattern Analysis and Machine Intelligence. 2021
- Mendoza, Hector and Klein, Aaron and Feurer, Matthias and Springenberg, Jost Tobias and Urban, Matthias and Burkart, Michael and Dippel, Max and Lindauer, Marius and Hutter, Frank: Towards Automatically-Tuned Deep Neural Networks In: AutoML: Methods, Sytems, Challenge. 2019
CAAFE: LLMs for Feature Engineering
While AutoML has focused on the numerical values for each feature of the dataset, little attention has been received to the human-priors related to tabular data. Tabular data often has column names and descriptions that accompany them, which has eluded any use for AutoML.
Introducing CAAFE, a feature engineering method designed for tabular datasets. It leverages the power of large language models (LLMs) to iteratively generate additional semantically meaningful features for tabular datasets based on the description of the dataset. The method produces both Python code for creating new features and explanations for the utility of the generated features.
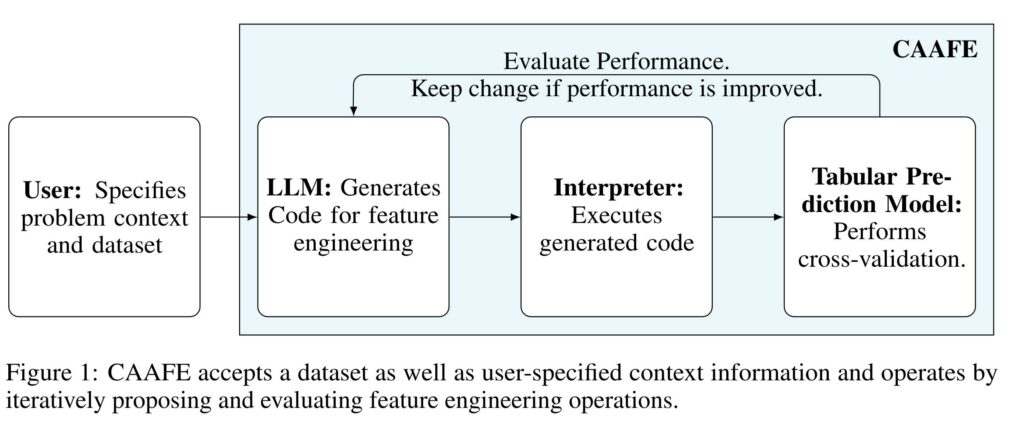
CAAFE emphasizes the significance of context-aware solutions that can extend the scope of AutoML systems to semantic AutoML. By incorporating domain knowledge into the AutoML process, CAAFE automates feature engineering for tabular datasets, generating semantically meaningful features and explanations of their utility.
The method is not only effective but also interpretable, providing a textual explanation for each generated feature. This makes the automated feature engineering process more transparent, enhancing the interpretability of AI models.

CAAFE is a promising step towards more extensive semi-automation in data science tasks. It paves the way for more context-aware solutions, potentially freeing up data scientists to focus on higher-level problem-solving and decision-making activities. As AI technologies continue to evolve, tools like CAAFE will play a crucial role in shaping the future of data science.
Usage
from caafe import CAAFEClassifier
from tabpfn import TabPFN
clf = TabPFN()
caafe_clf = CAAFEClassifier(
base_classifier=clf,
llm_model="gpt-4",
iterations=2
)
If you are interested in trying it out, you can find the github link here:
References
Noah Hollmann and Samuel Müller and Frank Hutter, LLMs for Semi-Automated Data Science: Introducing CAAFE for Context-Aware Automated Feature Engineering In: arXiv. 2023
AutoML-Benchmark
One of the primary reasons AutoML systems for tabular data have been so effective is the ability to comparably measure performance between different systems. This benchmark effectively evaluates just how good an AutoML system really is, allowing the field to greatly benefit from being able to track what is state-of-the-art, what works and what doesn’t.
You can check out their website (external)!
References
- Gijsbers, P. and LeDell, E. and Poirier, S. and Thomas, J. and Bischl, B. and Vanschoren, J., An Open Source AutoML Benchmark In: AutoML Workshop at ICML 2019
- Gijsbers, P. and Bueno, Marcos L. P. and Coors, S. and LeDell, E. and Poirier, S. and Thomas, J. and Bischl, B. and Vanschoren, J. AMLB: an AutoML Benchmark In: arXiv. 2022
Other Tools
There are a variety of other AutoML systems for tabular data that are out there, each with their own strengths and weaknesses. The success of AutoML research has even sparked large companies such as Microsoft, Amazon and Google to develop their own bespoke AutoML systems.
TPOT
One of the earlier AutoML Systems, TPOT uses evolutionary search methods to find pipelines from simple to exotic for to maximize performance.
- [Repo]
GAMA
Another customizable AutoML tool using multi-fidelity optimization and ensembling as efficient techniques to find pipelines.
- [Repo]
H2O
Both an open-source and paid service, H20 was one of the first companies to offer AutoML as a service, using ensembling techniques to find performant and complimentary pipelines.
- [Website]
Microsoft – FLAML
FLAML boasts a dominant performance when your budget to find a suitable model is small … very small. When applications depend on fast AutoML for user applications such as spreadsheets, timing is everything. By efficiently trying out a large variety of cheap models, they obtain good results and fast. While other AutoML systems boast a higher performance given enough time, FLAML gives decent results and fast.
- [Website]
Amazon – AutoGluon
AutoGluon is Amazon’s answer to AutoML for practitioners. Even without HPO, AutoGluon achieves state of the art with an exhaustive approach to meta-learning what models are generally good for a given problem and using enemsemble techniques like stacking, they provide efficient models and fast. AutoGluon also has support for a variety of modalities beyond just simple tabular csv’s, also incorporating text and images into their inference pipelines.
- [Website]
Google – Google AutoML
The success of AutoML systems in enabling non machine learning to understand and utilize their data has lead to Google’s own cloud based product, Google AutoML. This enables evens practitioners with limited compute to utilize the cloud for their problems.
- [Website]
AutoWeka
[This project is led by our close collaborators at UBC.] Many different machine learning algorithms exist that can easily be used off the shelf, many of these methods are implemented in the open source WEKA package. However, each of these algorithms have their own hyperparameters that can drastically change their performance, and there are a staggeringly large number of possible alternatives overall. Auto-WEKA considers the problem of simultaneously selecting a learning algorithm and setting its hyperparameters, going beyond previous methods that address these issues in isolation. Auto-WEKA does this using a fully automated approach, leveraging recent innovations in Bayesian optimization. Our hope is that Auto-WEKA will help non-expert users to more effectively identify machine learning algorithms and hyperparameter settings appropriate to their applications, and hence to achieve improved performance.