A radically new approach to tabular classification: we introduce TabPFN, a new tabular data classification method that takes < 1 second & yields SOTA performance (competitive with the best AutoML pipelines in an hour).
So far, it is limited in scale, though: it can only tackle problems up to 1000 training examples, 100 features and 10 classes. It works best when all features are numerical and there are no missing values (but we believe when we focus on those cases we’ll also improve performance for them).
TabPFN is radically different from previous ML methods. It is a meta-learned algorithm and it provably approximates Bayesian inference with a prior for principles of causality and simplicity. Qualitatively, its resulting predictions are very intuitive as well, with very smooth uncertainty estimates:
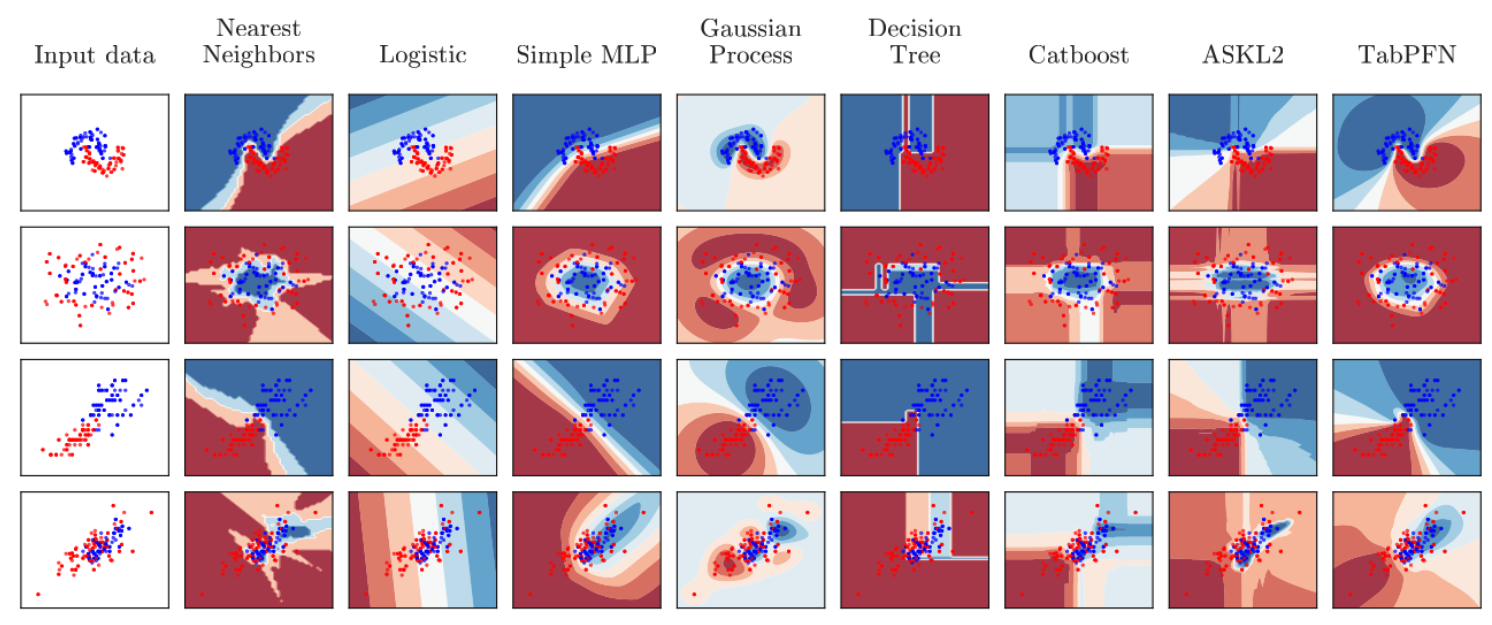
TabPFN happens to be a single transformer, but this is not the usual “trees vs nets” b a t t l e. Given a new dataset, the TabPFN does not use costly/unreliable gradient-based training, does not overfit when facing small datasets, and does not require any tuning. Rather, it performs a single forward pass of a fixed network: you feed the training data in as a set-valued input, along with $latex x_{test}$; the network then outputs probabilities for $latex y_{test}$.
TabPFN has been pre-trained to approximate Bayesian inference for precisely this task as visualized in this figure. 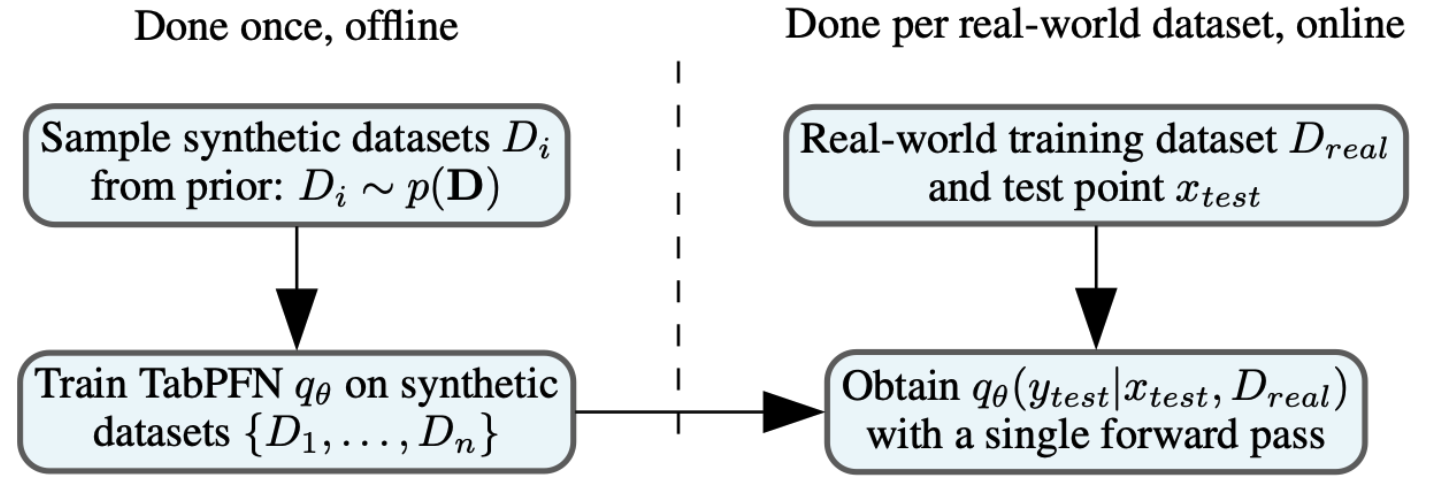 In the offline pre-training phase, we generated millions of synthetic datasets by sampling from our prior of what datasets might look like and trained the TabPFN to predict held-out points for each of them with a single forward prop. The TabPFN prior is based on structural causal models and generates data by sampling such models, with a bias for simplicity. Bayesian inference over this prior integrates predictions over the space of structural causal models, weighted by their likelihood given the data and probability in the prior – this captures the underlying uncertainty over different causal explanations for the data. On a new dataset, a single forward-pass then approximates Bayesian inference for our prior.
In the offline pre-training phase, we generated millions of synthetic datasets by sampling from our prior of what datasets might look like and trained the TabPFN to predict held-out points for each of them with a single forward prop. The TabPFN prior is based on structural causal models and generates data by sampling such models, with a bias for simplicity. Bayesian inference over this prior integrates predictions over the space of structural causal models, weighted by their likelihood given the data and probability in the prior – this captures the underlying uncertainty over different causal explanations for the data. On a new dataset, a single forward-pass then approximates Bayesian inference for our prior.
The transformer thus learned to act as a classification algorithm in a single forward pass. Ultimately, classification algorithms make computations on the data, and so does the TabPFN‘s forward pass. The TabPFN thus implements an algorithm that has been meta-learned in a gradient-based manner to minimize its predictive errors. And since this works in millions of training data sets, maybe it shouldn’t be surprising that this works on test data sets as well 🙂
Imagine what you can do with the TabPFN‘s almost instantaneous predictions. Real-time ML with a single forward pass of a single neural net, an operation that is extremely portable across platforms and trivial to deploy. Also on smartphones, sensors, etc. Go, #GreenAutoML! (Granted, there are many other fast classifiers, e.g. random forests; TabPFN gives you their speed paired with a performance rivalling today’s best AutoML methods run for up to an hour.)
A qualitative analysis along the lines of the excellent paper of Léo Grinsztajn, Edouard Oyallon and Gaël Varoquaux (https://hal.archives-ouvertes.fr/hal-03723551) shows that the TabPFN in many ways still behaves similarly to other neural network approaches, but with very strong performance. This might point to interesting future work on priors that incorporate more of the features traditionally attributed to tree-based approaches.
This line of work on TabPFNs offers something for many to like: classical data scientists who need fast methods, deep learners, Bayesians, meta-learners, etc. This might lead to an exciting new community forming.
- Classical data scientists: a dream come true — being able to address small datasets without having to worry about overfitting. So far, the best answer for small datasets was a random forest. TabPFN clearly statistically significantly outperforms these in our experiments on 179 datasets (even for the categorical datasets we didn’t focus on). Another upside is strong performance & quick execution without any need for tuning. Another classical approach with these desiderata are gradient boosted decision trees (XGBoost, CatBoost, LightGBM,…), and our experiments suggest that TabPFN is faster and outperforms these statistically significantly on numerical datasets. On categorical datasets, TabPFN and XGBoost perform comparably. TabPFN also has very different inductive bias than other approaches, making it quite uncorrelated with other methods; thus, it can be ensembled with other techniques very effectively.
Caveats? Our limitations to 1000 training examples, 100 features and 10 classes. And there is large variance; you’ll find datasets where any classification approach works poorly, including TabPFN. You’ll also find datasets where SVMs, RFs, and GB outperform TabPFN. Our statistically significant improvements hold only across datasets and not on every single dataset.
- Deep learners: this is the natural progression from the many recent works on novel architectures, regularizers, etc, for tabular data. Unlike those, we use the latest methods in deep learning, in particular in-context learning, and we don’t have the potential downsides of those methods (such as costly training of neural nets for the new dataset or overfitting for small datasets).
- Bayesians: another dream come true — computing a close approximation to the posterior predictive distribution as quickly as a single forward pass. In contrast to standard Bayesian deep learning, this also works for complex priors, over various architectures, initial weights, etc.
- Meta-learners: finally, an application where meta-learning yields state-of-the-art performance. While the community at large still uses networks pretrained on ImageNet/JFT-300 instead of MAML, and while we still all use Adam instead of learned optimizers, we convincingly show the power of meta-learning in practice. The meta-learned TabPFN appears to be better suited to handle small tabular data than decades of manually-created algorithms and as such is directly applicable in practice.
Why are we currently limited to small data? The limit to 1000 training data points is due to standard transformer memory and compute requirements being quadratic in the input length. There is lots of current work aiming to overcome this limit, which would also apply to us. The limits to 100 features and 10 classes are mostly in place to keep the training time reasonable (1 machine with 8 GTX2080s for 20h). We so far have focussed our prior on numerical data without missing values, that’s why performance is better on datasets with those characteristics.
Can we overcome these limits? Well, we‘ve scaled from balanced binary classification on 30 data points earlier this year (https://arxiv.org/abs/2112.10510) to 1000 data points and imbalanced data now. We‘ll continue to scale, but the rate will slow as we‘re exploiting the low-hanging fruits.
We expect our radical claims to be met with initial skepticism. That is healthy for science! Please check out our paper for details and poke holes where you can. We open-source all our code, including an sklearn interface and a Colab notebook demonstrating its use. We also have 2 demos: One to experiment with the TabPFNs predictions (https://huggingface.co/spaces/TabPFN/TabPFNPrediction) and one to check cross-validation ROC AUC scores on new datasets (https://huggingface.co/spaces/TabPFN/TabPFNEvaluation).
This is NOT the end of the story. It’s just the beginning. There are dozens of possibilities for future work on which we’d love to join forces. Please share this broadly if you know data scientists who’d like to try a cheap SOTA method for small tabular data. Repeat disclaimer: so far, this is limited to problems with no more than 1000 data points, 100 features and 10 classes, and it’s better on numerical datasets without missing features.
Also, if you’d like to join us to extend this, we‘re hiring exceptional talents for PhD, postdoc and research engineer positions, in the context of ELLIS and our ERC consolidator Grant on „Deep Learning 2.0“ (see https://www.automl.org/deep-learning-2-0-extending-the-power-of-deep-learning-to-the-meta-level/). Please apply here: https://ml.informatik.uni-freiburg.de/positions/
Full paper: https://arxiv.org/abs/2207.01848
Code: github.com/automl/TabPFN
Colab notebook with a scikit-learn interface: https://colab.research.google.com/drive/194mCs6SEPEW6C0rcP7xWzcEtt1RBc8jJ?usp=sharing
Our demos for prediction on a table and viewing the ROC AUC for a table (Both of them run on a weak CPU, the Colab can be faster with GPU).